OpenSCAD-Bench: an LLM benchmark
Every once in a while over the years, I would ask an LLM to write OpenSCAD (a programmatic 3D CAD modeling language) code for some simple object. The results have usually been pretty bad. Although syntactically valid OpenSCAD was the norm, the resulting models were usually some form of abstract garbage.
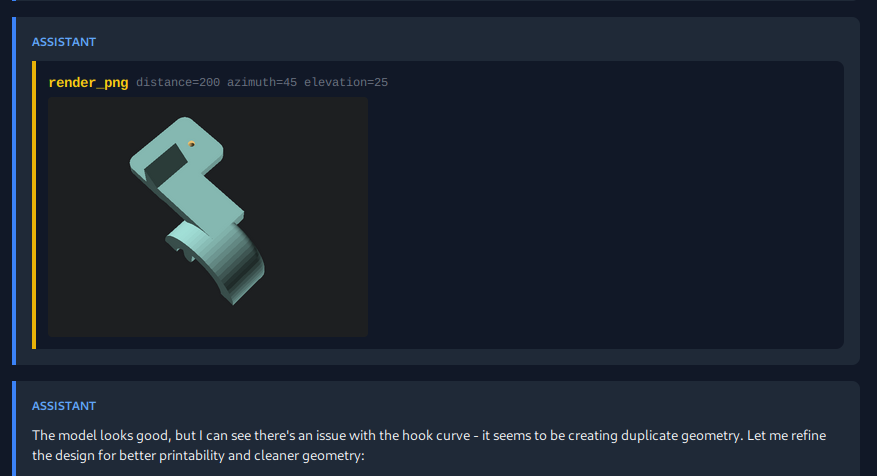
For example, this is Sonnet's 4.5 attempt at a towel hook:
But, with the late 2025 batch of LLMs, the results are not that horrible anymore. With this in mind, I have constructed a small benchmark for modeling several objects. It demonstrates a surprising variability in capabilities across the different frontier models, ranging from "abstract art" to objects that are manufacturable with a 3D printer and can be used in the real world.
The benchmark showcase is available here, with the source code living on GitHub.

The agent loop bare bones: the LLMs have the ability to render the OpenSCAD code they submitted, figure out using their multimodal capabilities whether they have achieved the goal or not and then iterate on their code until they are satisfied with the result.
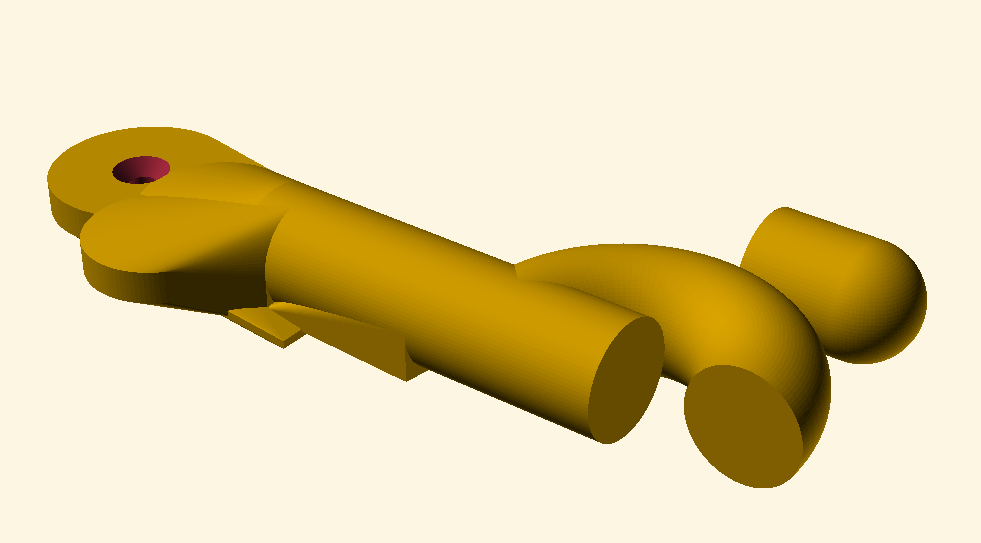
As of today, it seems that the Gemini is the best performing model, often producing models that are not only visually correct but also manufacturable. I am adding models on an ongoing basis, so this benchmark will continue to hopefully evolve over time.
Checking the traces is pretty interesting, in particular as it shows the significant limitations of the current multimodal capabilities. For example, below is a screenshot from Opus 4.5 failure to model a towel hook.
As far as I can tell, there is a pretty significant "r's in strawberry" effect, where the visual understanding of the model is at a much higher level than raw pixels, meaning often even completely mangled geometry is recognized a "looking good". The input image corpus is just very unlikely to contain many mangled geometry 3D model screenshots.